By: Denekew A. Jembere
 Licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Introduction
The quality of insights or the robustness of data prediction models depends not only on the overall analysis technique or process but also on the quality and its representativeness of the real business scenario of the data used in the analysis process. In relation to data quality, data that doesn’t represent the most commonly observed feature value combinations or doesn’t fit within potential classes of data, from the dataset, is considered as an outlier. Such data can be caused either by unusual transactions, such as fraud or due to data measurement, data entry or data sampling issues. Identifying such outliers that do not meet logic guidelines for human intervention can be done using data mining techniques and tools.
Therefore, this article outlines the identification of outliers, in a selected dataset, applying the clustering technique using the SQL Server Analysis Service (SSAS) Data Mining Add-in on Microsoft Excel. The outlier values detected and, the impact of the respective attributes (features) on the overall dataset, if a prediction model is to be created, are evaluated using the Naïve Bayes and Decision Tree dependency networks.
Data Mining for decision making in organizations
Focusing on optimization and data mining for decision making, Abu Haris et al (2014) underlined the importance of data mining for predicting future trends and performance, whereby enabling decision-makers to make forecasting based on historical data. In this regard, analysis of organizational data using data mining algorithms enables to discover interesting patterns, such as outliers or fraud transactions, and meaningful relationships between features or attributes of the data.
According to Sharma and Mansotra (2016), effective use of data mining techniques and models for decision making can be achieved by combining the necessary data mining skills and iterative improvement of the resulting data mining models. In this regard, organizational businesses and their landscapes are shifting dynamically, which is also reflected in the data that they collect from their customers and other business operations. So, iterative evaluation and improvement of data mining models by using key performance indicators (KPIs) and the latest data reflecting the current state of the business improves the decision making process.
Data Mining for outlier or anomaly detection
Unsupervised learning like cluster algorithms (Tlusty & et al., 2018) can be applied to identify patterns and segment a heterogeneous population into a smaller number of more homogenous subgroups or clusters. Such a cluster segmentation technique is applicable in real-business scenarios like discovering distinct groups of customers based on products or services purchase historical data or identifying groups of houses in a city based on utility service consumptions data.
The huge amount of transactional data in businesses that might contain outliers like fraudulent transactions is very difficult for human intervention or review. Clustering expectation-maximization method (Qin & et al., 2013; Yao & et al., 2018) enables to detect such outliers and anomalies that do not fit any model or belong to clusters that cover regular transactions. As used in Wang & et al (2017), outlier detection has become a common technique in data preprocessing so that the outlier data gets excluded and its impact on the model to be built can be eliminated.
Target dataset for data mining
The vTargetMail in the AdventurWorksDW database (Microsoft, 2017) which has 18,484 records represented by 32 attributes is used for the outlier detection exercise, using the data mining clustering algorithm on Microsoft Excel and SQL Server Analysis Service (SSAS). The partial view of the selected dataset’s data for the clustering process is shown in Figure 1 below.
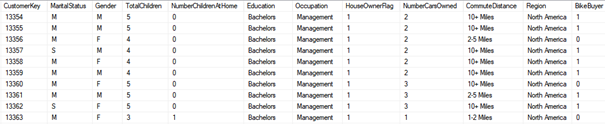
Detecting Outlier in the target dataset
Using soft clustering, or Expectation-Maximization clustering in Excel integrated with SSAS, the target dataset (vTargetMail, discussed above) can be analyzed to find suspicious values and detect the rows containing these outliers. Using the table analysis tool in the Excel data mining add-ins (Milener, 2018), Highlight Exceptions, the analysis of the target data highlights suspicious values and raws in the datasets as shown in Figure 2.
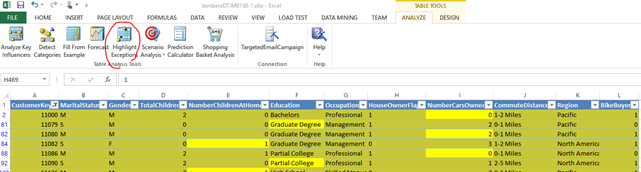
Apart from its infeasibility to fully review the dataset, each of the outliers identified by the tool may not be readily explainable, just picking a record containing from the dataset. So, once the suspicious values and rows containing them get identified, a focused human intervention, with sufficient domain knowledge, helps to gain insight into the cause of the records with these suspicious values and their respective attributes.
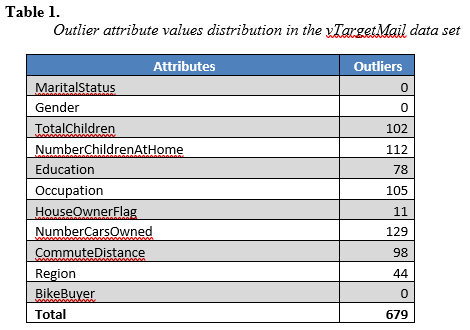
In addition to highlighting the outlier values and rows in the dataset, the table analysis tool generates a summary report of the records and outlier values distribution in the dataset, which can be used to tune the impact of the outlier values based on an exception threshold percentage value, which indicates the percentage of the outliers to be ignored. For the target dataset, vTargetMail, setting the outlier exception threshold to 75% (honoring the value set by the analysis tool), a total of 679 records are identified as outliers with the attribute values distributed as shown in Table 1. Comparatively, the NumberCarsOwned attribute has the highest outlier count, having a higher influence on the total number of outliers and, MaritalStatus, Gender and BikeBuyer attributes are not affected at the selected exception threshold percentage.
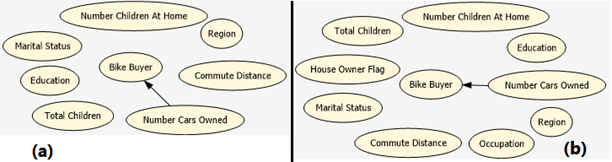
According to Yao et al (2018), outlier or anomaly detection of data can be optimized by using multiple feature selection and machine learning classification techniques. In this regard, combining data mining techniques: Clustering – to identify the outlier values and their distribution in the dataset attributes; Naïve Bayes and Decision Tree – to see the relationships between attributes, help to achieve a better result in the analysis.
Using the same dataset the Naïve Bayes and Decision Tree algorithms, analysis done here, revealed the attributes (or features) relationship and the level of strength of the relationship. Clustering as a data preprocessing and outlier detection technique can help to increase the robustness of the prediction model if the dataset is used to predict, for instance, potential bike buyers. As a result, the NumberCarsOwned, which has the highest influence on the outliers becomes an important attribute for explaining the bike buyers, as shown in Figure 3. Therefore, the outliers detected, in the clustering process, with an appropriate exception threshold percentage can be used to cleanse the data before building the prediction model.
Outlier detection in healthcare claims
For detecting healthcare claims outliers, Bauder and Khoshgoftaar (2016) proposed a novel approach that uses Bayesian inference, using probabilistic programming. In their approach, Bauder and Khoshgoftaar used the Medicare and Medicaid dataset, which they reduced the size by applying different criteria explained in their report, trained the outlier detection model and evaluated using two uses cases. Base on the results of the case studies, Bauder and Khoshgoftaar claim that their proposed approach effectively detects all outliers with corresponding probability distributions and can be used to detect fraudulent payments with associated probability detail.
The outlier detection techniques used by Bauder and Khoshgoftaar (2016), provides a different perspective to associate probabilistic information with the detected values, which seems similar to the exception threshold used in this article. As an input to the business’s strategic decision, Bauder and Khoshgoftaar used the outlier detection technique to detect fraudulent payments for healthcare claims.
References
Abu Haris, N., Abdullah, M., Othman, A.T., Rahman, F.A. (2014). Optimization and data mining for decision making. World Congress on Computer Applications and Information Systems (WCCAIS)
Bauder, Richard A., Khoshgoftaar, Taghi M. (2016). A Probabilistic Programming Approach for Outlier Detection in Healthcare Claims. 15th IEEE International Conference on Machine Learning and Applications (ICMLA)
Microsoft. (2017, December 17). AdventureWorks sample databases. Retrieved from Github: https://github.com/Microsoft/sql-server-samples/releases/tag/adventureworks
Milener, G. G. (2018, May 7). SQL Server Data Mining Add-Ins for Office. Retrieved from Microsoft, docs.microsoft.com: https://docs.microsoft.com/en-us/sql/analysis-services/data-mining/sql-server-data-mining-add-ins-for-office?view=sql-server-2017
Qin, B., Xia, Y., Li, F., & Ge, J. (2013). EMU: An expectation maximization based approach for clustering uncertain data. Journal of Intelligent & Fuzzy Systems, 25(4), 1067–1083.
Sharma, Anand, Mansotra, Vibhakar. (2016). Data mining based decision making: A conceptual model for public healthcare system. 3rd International Conference on Computing for Sustainable Global Development (INDIACom)
Tlusty, Tal, Amit, Guy, Ben-Ari, Rami. (2018). Unsupervised clustering of mammograms for outlier detection and breast density estimation. 24th International Conference on Pattern Recognition (ICPR).
Wang, Zhonghao, Huang, Xiyang, Song, Yan, Xiao, Jianli. (2017). An outlier detection algorithm based on the degree of sharpness and its applications on traffic big data preprocessing. IEEE 2nd International Conference on Big Data Analysis (ICBDA) Yao, Jianrong, Zhang, Jie, Wang, Lu. (2018). A financial statement fraud detection model based on hybrid data mining methods. International Conference on Artificial Intelligence and Big Data (ICAIBD)